|
|
|
|
IDEF1X is a data modeling technique that is used by many branches of the United States Federal Government. [See Bruce 1992.] The IDEF1X version of the sample model is shown in Figure 5.
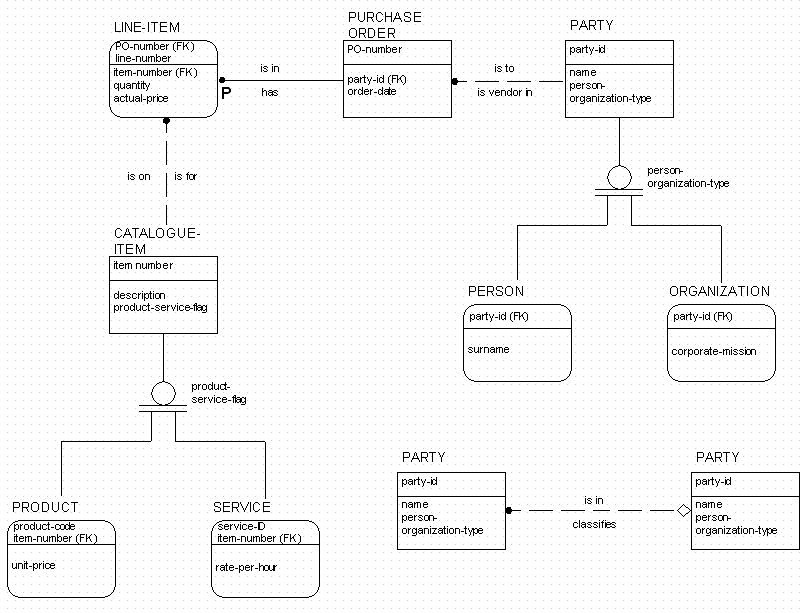
Entities and Attributes
Entities are shown by round-cornered or square-cornered rectangles. Round cornered rectangles represent "dependent" entities — those whose unique identifier includes at least one relationship to another entity. "Independent" entities, whose identifiers are not derived from other entities, are shown with square corners.
The name of the entity appears outside the box. The box is divided, with identifying attributes (again, the primary key) above the division and non-identifying attributes below.
In multi-word entity names, the words may be separated by hyphens, underscores, or blanks.
Relationships
In IDEF1X, relationships are asymmetrical: different symbols for optionality are used, depending on the relationship’s cardinality. Unlike the other notations, symbols cannot be parsed in terms of optionality and cardinality independently. Each set of symbols describes a combination of the optionality and cardinality of the entity next to it.
In addition to a relationship line from an entity, the foreign key that would implement the line in a relational database design is shown as an attribute of that entity.
If a relationship is part of an entity’s unique identifier, it is shown as a solid line; if not, it is shown as a dashed line.
Table 1 shows, for IDEF1X and the Barker notation, all the possible combinations of cardinality and optionality on both ends of the relationship.
Cardinality/Optionality
As seen in the table, optionality is shown differently for the "many" and the "one" sides of a relationship. Most of the time, a solid circle next to an entity means zero, one or more occurrences of that entity. If there is no other symbol next to the entity on this "many" side of a relationship, the relationship is optional. See lines 1-3, and 7 in Table 1. That is, the solid circle stands for zero, one or more ("may be . . . one or more") if it is by itself. Adding the letter P makes the relationship mandatory (meaning "must be one or more")*. Adding a "1" also makes the relationship mandatory, but this changes the cardinality of the relationship to one. It changes the meaning of the solid circle from "may be one or more" to "must be one and only one". (See lines 4-6, 8, and 10 in the Table.) Adding the letter Z keeps the relationship optional, but that changes the cardinality of the solid circle to ". . . one and only one".
So a solid circle may mean "must be" or "may be", and it may mean "one or more" or "one and only one", depending on the other symbols around it. That is to say, the solid circle does not convey any inherent meaning in itself.
Absence of a solid circle next to an entity means that only one occurrence of that entity is involved ("one and only one"). If there is no symbol next to the entity on the "one" side of the relationship, the entity is mandatory ("must be one and only one"), as shown in lines 1,2,4,5, 11-12, 14-15, 17 and 18.
Placing a small diamond symbol next to the entity means that the other entity in the relationship may be related to one and only one occurrence ("zero or one") of that entity. (See lines 3, 6, 16 and 19.) This then is an alternative way to to specify an optional one and only one occurrence an entity. We saw above that you could also use a solid circle with a letter Z under it (See lines 21-24.)
Since the solid circle — which usually represents "may be one or more" — always appears on the "many" side of a relationship, the use of the solid circle in a many to many relationship makes each end optional. Adding the letter "P" on one or both ends makes the end so modified mandatory. (See lines 7 through 10.)
The two ways of showing that an occurrence of one entity "must be" related to a single occurrence of another mean that there are four different ways to represent a mandatory one to one relationship. These are shown in lines 11-14. Similarly, optional one to one relationships can be shown in four different ways, as shown in lines 21-24. One to one relationships that are partly optional and partly mandatory can be shown in two ways, depending on which way the model is oriented, as shown in lines 15-18.
NOTE: The variations in notation above, which have no meaning in the conceptual model turn out to be significant in the physical design. The difference between representations for "may be one and only one" has to do with the fact that the diamond implies an optional foreign key in the opposite entity, while the circle with the z simply says that there may or may not be a child occurrence. In the other cases of multiple representation of the same concept (11-14, 15-16, 17-18, and 21-24), the culprit is again physical implementation. Each of the different symbol sets is implemented in a different way. Indeed, some of the symbol combinations cannot be implemented as expressed.
In other words, the symbols are deeply linked to the implementation of the tables, not the logic of the situation. Thus, IDEF1X is fundamentally a physical database design modeling technique, not one appropriate for doing conceptual design.
Names
A relationship name is a verb or verb phrase, where multiple words are separated by spaces. Relationships are identified in both directions.
|
Barker’s Notation |
IDEF1X Notation |
Barker Description |
IDEF1X Description |
|
|
1 |
|
|
Each A may be . . . one or more B’s. Each B must be . . . one and only one A. |
One to zero or more (dependent) |
|
2 |
|
|
Each A may be . . . one or more B’s. Each B must be . . . one and only one A. |
One to zero or more |
|
3 |
|
|
Each A may be . . . one or more B’s. Each B may be . . . one and only one A. |
Zero or one to zero or more |
|
4 |
|
|
Each A must be . . . one or more B’s. Each B must be . . . one and only one A. |
One to one or many |
|
5 |
|
|
Each A must be . . . one or more B’s. Each B must be . . . one and only one A. (A partially identifies B.) |
One to one or many (dependent) |
|
6 |
|
|
Each A must be . . . one or more B’s. Each B may be . . . one and only one A |
One to zero or many |
|
7 |
|
|
Each A may be . . . one or more B’s. Each B may be |
Zero or many to zero or many |
|
8 |
|
|
Each A must be . . . one or more B’s. Each B must be . . . one or more A’s. |
One or many to one or many |
|
9 |
|
|
Each A may be . . . one or more B’s. Each B must be . . . one or more A’s. |
Zero or many to one or many |
|
10 |
|
|
Each A must be . . . one or more B’s. Each B may be . . . one or more A’s. |
One or many to zero or many |
Table 1: Comparison of Barker’s and IDEF1X Notations
("..." represents the relationship name.)
|
Barker’s Notation |
IDEF1X Notation |
Barker’s Description |
IDEF1X Description |
||
|
11 |
|
|
Each A must be . . . one and only one B. Each B must be . . . one and only one A. |
One to one |
|
|
12 |
(Same as 11) |
|
(Same as 11) |
One to one |
|
|
13 |
(Same as 11) |
|
(Same as 11) |
One to one |
|
|
14 |
(Same as 11) |
|
(Same as 11) |
One to one |
|
|
15 |
|
|
Each A must be . . . one and only one B. Each B must be . . . one and only one A. (B partially dependent on A.) |
One to one (dependent) |
|
|
16 |
(Same as 15) |
|
(Same as 15) |
One to one (dependent) |
|
|
17 |
|
|
Each A must be . . . one and only one B. Each B may be . . . one and only one A. |
Zero or one to one |
|
|
18 |
(Same as 16) |
|
(Same as 16) |
Zero or one to one |
|
|
19 |
|
|
Each A may be . . . one and only one B. Each B must be . . . one and only one A. |
One to zero or one |
|
|
20 |
|
|
Each A may be . . . one and only one B. Each B must be . . . one and only one A. (A partially identifies B.) |
One to zero or one (dependent) |
Table 1: Comparison of Barker’s and IDEF1X Notations, continued
("..." represents the relationship name.)
|
Barker’s Notation |
IDEF1X Notation |
Barker’s Description |
IDEF1X Description |
|
|
21 |
|
|
Each A may be . . . one and only one B. Each B may be . . . one and only one A. |
Zero or one to zero or one |
|
22 |
(Same as 19) |
|
(Same as 19) |
Zero or one to zero or one |
|
23 |
(Same as 19) |
|
(Same as 19) |
Zero or one to zero or one |
|
24 |
(Same as 19) |
|
(Same as 19) |
Zero or one to zero or one |
Table 1: Comparison of Barker’s and IDEF1X Notations, continued ("..." represents the relationship name.)
Unique identifiers
As stated above, a unique identifier is represented in IDEF1X by the primary key which will implement it in a relational data base. Since all relationships are shown by foreign key attributes, the primary key may consist of any combination of foreign key and non-foreign-key attributes. If a foreign key is present in the unique identifier primary key, then the otherwise dashed relationship line becomes solid, and the entity box acquires round corners.
Sub-types
IDEF1X shows sub-types as separate entity boxes, each removed from its super-type and connected to it by an "isa" relationship. (Each occurrence of a sub-type "is a[n]" occurrence of the super-type.)
There are two kinds of sub-types. In Figure 5, the circle with two horizontal lines under it is a complete sub-typing arrangement: all occurrences of the parent must be occurrences of one or the other sub-type. A circle with only one horizontal line below it is an incomplete sub-typing arrangement: the sub-types do not represent all possible occurrences of the super-type.
All sub-types extending from a single sub-type symbol are mutually exclusive. Sub-types may be shown to be not mutually exclusive by being descended from different sub-type symbols attached to the same super-type entity.
In IDEF1X, the unique identifier of the sub-type must always be identical to the identifier of the super-type. This point is reinforced by including the foreign key ("(FK)") designator next to the unique identifier of the sub-type, referring to the unique identifier of the super-type. Optionally, a "role name" may be appended to the front of the foreign key name in the sub-type. In Figure 5, the role names "product-code" and "service-id" are roles, appended to "item number" for the primary keys of product and service. Note that since the keys themselves remain identical to the key of the super-type, appending role names does not change their format in any way.
An attribute used to discriminate between the sub-types is placed next to the sub-type symbol. For example, "person-organization-type" is shown in Figure 5, above, to distinguish between occurrences of person and organization.
Constraints between relationships
IDEF1X does not have an explicit way to represent constraints between relationships. Instead of saying "A" is related to "B" or to "C", it is necessary to define an entity, "D", and then use the sub-type notation. Thus you would say "A" is related to "D", which must be either a "B" or a "C".
The ability to express exhaustiveness and exclusivity in sub-types does carry over to this situation.
This is shown in Figure 5 with the creation of catalogue item, as a super-type of product and service.
Comments
IDEF1X symbols do not map cleanly to the concepts they are supposed to model. A concept that should be represented by a single symbol requires several together and it requires different symbols under different circumstances. That is, particular situations can be represented by more than one set of symbols, while the same symbol can mean different things, depending on context. Which symbol is used to describe a particular situation is heavily dependent on the context of that situation and on how the relationship will be implemented, not just on the situation itself.
For example, the symbol to be used for optionality depends on the cardinalty of the relationship. The solid circle symbol can mean anything, depending on its setting. Similarly, a cardinality/optionality combination may be represented in different ways. This is because what is being represented is not a conceptual structure, but an implementation method.
The effect of all this is that it is prohibitively difficult to teach a non-technical viewer to read an IDEF1X diagram.
A dominant graphic feature of any relationship line is its being solid or dashed. Barker’s notation uses this feature to distinguish between relationships that are required and those that are not. Among those relationships that are, those participating in a unique identifier may be simply marked with an extra line across them, but this level of detail is often not required.
In IDEF1X, however, the solidity of a line describes the participation of one entity in the unique identifier (primary key) of the other. This requires the analyst to begin h’ efforts by analyzing dependency — before addressing the optionality or cardinality of the model’s relationships.
In a real modeling situation, however, an analyst in fact normally starts by examining which entities are required for which other entities, and how many occurrences are involved. The details of keys or identifiers are typically not addressed until much later.
And corrections to the model are unnecessarily difficult: If you make a single error in cardinality or optionality (say the one to one mandatory relationship should really be optional), then several symbols must be changed.
While it does permit showing multiple inheritance and multiple type hierarchies, the multi-box approach to sub-types takes up a lot of room on the drawing, limiting the number of other entities that can be placed on it. It also requires a great deal of space to give a separate symbol to each attribute and each relationship. Moreover, it does not clearly convey the fact that an occurrence of a sub-type is an occurrence of a super-type.
IDEF1X may be a good modeling tool to use as the basis for data base design, but it does not follow the rules of good graphic design (as described in the introduction to this article, above), making it unnecessarily difficult to learn and difficult to use as a tool for analyzing business requirements jointly with users.